May 7, 2026·15 min read
The Evolution of AI Agentic Patterns
Prompt engineering taught us how to talk to models. Context engineering taught us what to feed them. Harness engineering is teaching us how to build systems around them. This is how the field's central question has shifted three times in four years — and what each shift actually required.

When ChatGPT went mainstream in late 2022, the interaction was deceptively simple: type a question, marvel at the answer. That simplicity was the beginning of a discipline — and over the following four years, that discipline grew substantially in scope, rigor, and infrastructure. What started as an art of clever phrasing has become full system architecture. The field's central question has shifted three times.
In 2022, it was "what should I say?" — and prompt engineering was the answer. By 2023, it became "what information should I feed the model?" — and context engineering emerged. Today, the question is "what system do I need to build?" — and the answer is harness engineering.

Each shift happened because the previous generation hit a wall it could not climb through better technique alone. Prompt engineering couldn't solve the knowledge cutoff. Context engineering couldn't solve reliability. Harness engineering is the infrastructure layer that addresses what neither prompt craft nor context management could: making agents that work consistently in production, across sessions, across failures, and across users. This post traces all three generations — what each one solved, why it wasn't enough, and what had to be built next.
This article was inspired by the talk "Build an Agent Harness with Microsoft Agent Framework and GitHub Copilot SDK" delivered by Thang Chung at Global Azure 2026 (DevCafe Vietnam, April 18, 2026) 1. The concepts introduced in that session prompted a deeper exploration — the references, research, and writing that followed became this post. View slides here
1. Prompt engineering
From 2022 through most of 2024, the central challenge was figuring out how to talk to a model. LLMs are trained on vast corpora of human knowledge — books, code, papers, conversations — and that knowledge gets compressed into billions of parameters. If the knowledge is already inside the model, then the only variable left is how you phrase your request. Write the right words, in the right structure, and you unlock the right answer.
So we did the one thing we could: we wrote to it. The craft lived entirely in the prompt text — the exact words, structure, and instructions you handed to the model. Get it right, and the model performed beautifully. Get it wrong, and you got something generic or hallucinated.
And for a while, it worked remarkably well. Techniques like Chain-of-Thought ("let's think step by step"), few-shot examples, and role prompting produced genuinely impressive results. Prompt engineering became a discipline, then a job title, then almost a mythology.2
The hottest new programming language is English. — Andrej Karpathy, 2023
system_prompt = """
You are a coding assistant.
Rules:
- Return JSON only
- Never skip edge cases
- Use snake_case
"""
response = openai.chat(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
]
)
# No memory. Every call starts from scratch.
But the limits were structural, not stylistic. LLMs are frozen in time — their knowledge ends at a training cutoff. They don't know what your company shipped last week, what your internal policy says, or what error your system threw five minutes ago. And no matter how cleverly you phrase the question, the model cannot answer accurately from knowledge it simply doesn't have. The bottleneck had shifted: the problem was no longer what you said — it was what the model could see.

2. Context engineering
Context engineering emerged toward the end of 2023, driven by that realization: writing a better prompt wasn't enough if the model was operating blind. The real question became what to load into the context window — the full composition of everything the model sees before it generates a response.3
In an agentic loop, that context is never static. At each turn, more information gets assembled:
- Conversation history — previous turns in the dialogue
- Knowledge retrieval — relevant documents pulled from external sources via RAG
- Tool results — outputs from MCP tools the agent has called, including failures it can learn from The prompt is no longer something you write once. It becomes a dynamic assembly that gets rebuilt on every single turn — growing, shifting, and accumulating state. And context windows have a hard limit.
Two techniques emerged to fight it, with fundamentally different trade-offs:
Compaction (reversible): Strip out information that already exists in the environment. If the agent wrote a 500-line file, store only the path — the agent can re-read it when needed. Signal stays intact. Claude Code implements this by compressing context while keeping the five most recently accessed files always available.3
Summarization (lossy): Use an LLM to rewrite history into natural language. High compression, human-readable — but permanently lossy. A detail summarized away is gone forever.
Prefer raw context > compaction > summarization. Use lossy compression only as a last resort.
But even with these techniques, a deeper problem remained. When a model summarizes its own conversation history, it becomes biased toward whatever it chose to remember. Important details get quietly dropped. RAG helps by pulling only what's relevant on demand. Dynamic tool selection keeps the MCP tool list lean. All of it is the same underlying constraint: the context window is finite, and every token is a choice.3
Context engineering made agents smarter. It didn't make them reliable. For that, you needed something more than a well-crafted prompt or a well-managed window — you needed a system. That shift is what harness engineering addresses.
3. Harness engineering
Then, toward late 2025 going into 2026, a blog post started circulating that put a name to where things were heading. Mitchell Hashimoto — co-founder of HashiCorp — wrote My AI Adoption Journey, and in it he introduced the term harness engineering.

What Hashimoto described wasn't prompt tuning. It was a fundamentally different relationship to failure: mistakes aren't quietly absorbed — they get encoded as permanent constraints on the system. Hashimoto describes two concrete forms this takes:
Better implicit prompting via AGENTS.md. A constraint file where each line represents a real bad agent behavior that has been observed and prevented. Simple, durable, accumulates correctness over time.
Actual programmed tools. Scripts, type checkers, verification harnesses. If an agent keeps calling an API incorrectly, write code that requires API calls to pass type checking. Encode human judgment into system constraints that the agent can't bypass.
# AGENTS.md — accumulated constraints from real failures
## Rules
- Never modify migration files
- All DB writes must go through the service layer
- Run tests before marking any task complete
- Never delete files without confirmation
Not the prompt. Not the context. The system. This gave a name to what forward-thinking teams had been quietly building: Harness Engineering — the design of the full infrastructure surrounding the model. Tools, memory, sandboxes, orchestration, error recovery, evaluation loops, security guardrails. After Hashimoto's post circulated, you started hearing the term everywhere — teams building serious AI products, LangChain shipping their Open Deep Research project on LangGraph, companies rethinking their entire infrastructure.
The rigor has quietly shifted from prompt text toward system architecture. The question is no longer "how do I write a good prompt?" — it's "what do I actually want to build?"
LangChain captured it cleanly in March 2026:
Agent = Model + Harness
The model contains the intelligence and the harness makes that intelligence useful. The harness is every piece of code, configuration, and execution logic that isn't the model itself. The model provides stateless token prediction. The harness provides everything that makes that useful: memory, tools, constraints, sandboxing, orchestration, feedback.
A harness has six layers, flowing from user interface down to the model:
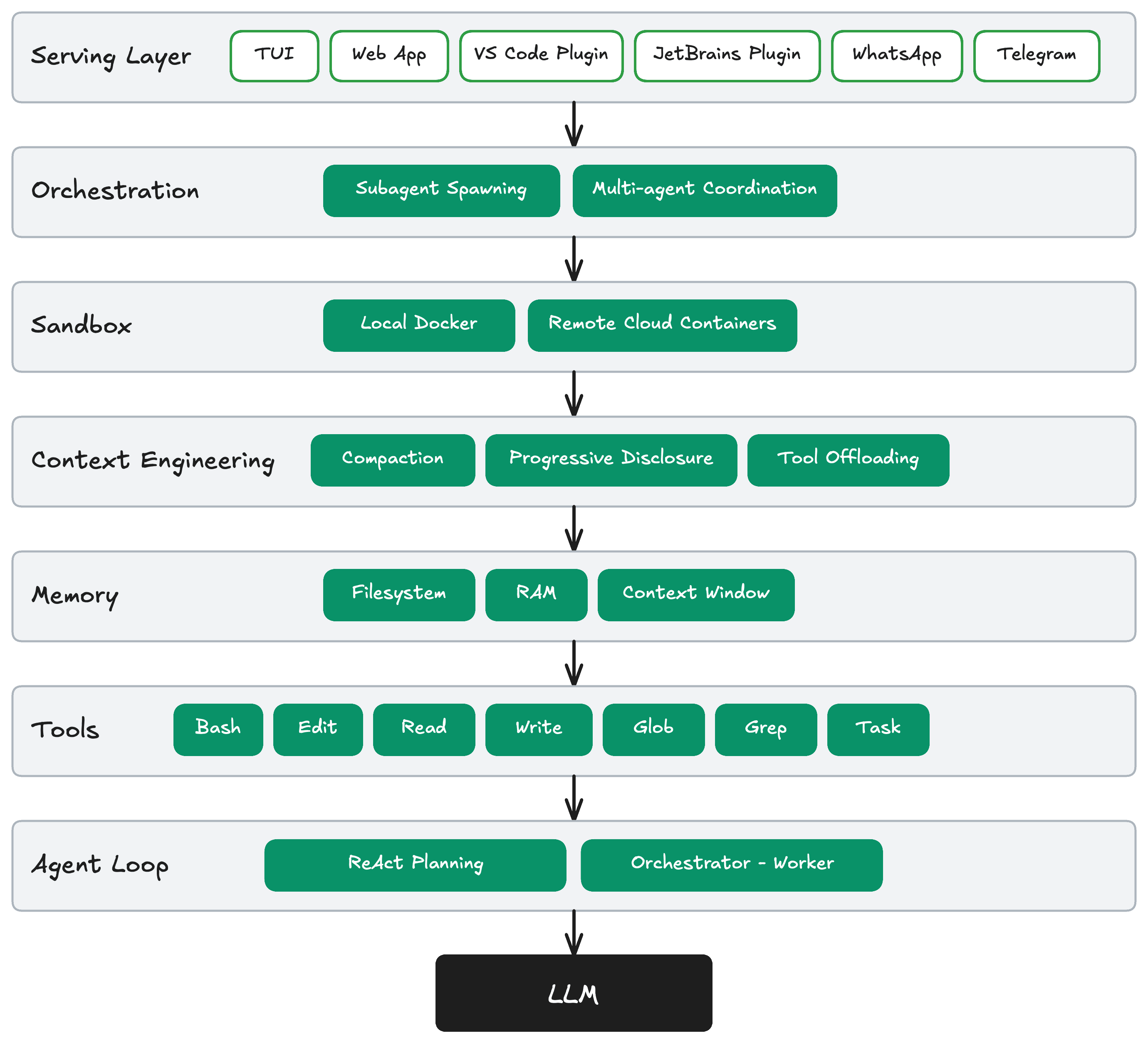
3.1 Serving Layer
The serving layer is how the agent receives input and delivers output. The key insight from OpenClaw's architecture is the Channel abstraction: rather than deploying separate bots per platform, a single Gateway process receives messages from different platforms and routes them into the same session store.4
One OpenClaw instance, connected to multiple chat platforms. Same brain, same memory, same agent. If you start a conversation on WhatsApp and continue on Telegram, OpenClaw keeps the thread because the context is shared.4
Supported surfaces span WhatsApp, Telegram, Slack, Discord, Signal, iMessage, Google Chat, Microsoft Teams, Matrix, Zalo, and 50+ others.5 Each channel plugin authenticates, receives messages, and sends responses — but the agent behind them is identical.6
The critical difference between channels is the richness of context they provide:
- TUI / IDE plugins (VS Code, JetBrains) — richest context; agent sees open files, cursor position, active errors
- Web app — moderate context; accessible without installation
- Messaging (WhatsApp, Telegram, Slack) — leanest context; text only, but meets users where they already are The Gateway normalizes all of these into a unified session format before the agent ever sees them.6
3.2 Orchestration
Orchestration is not the entry point for requests — that is the serving layer's responsibility. Orchestration is the routing and decomposition logic: given a task, decide how to split it and who handles what. Think of it like OpenRouter — not a gateway, but intelligent routing.
Two patterns dominate:
Subagent Spawning: The parent agent creates a child agent. On spawn, it writes a new prompt, assigns a specific tool set, and replicates its context window into the child — the child has enough context to work independently. Inside Claude Code's "Agent Teams" feature (revealed by the March 2026 source leak): one session acts as team lead, spawns independent sub-agents that work in parallel, each with their own context, communicating via a shared task list with dependency tracking.7
Multi-agent Coordination: The task is decomposed and the context window is split across specialized agents. Each agent sees only its relevant slice. The orchestrator collects and aggregates results. Unlike spawning, context is not replicated — it is divided.
The key difference: spawning copies context and delegates one task; multi-agent coordination decomposes the problem and gives each agent only its part.
3.3 Sandbox
Agents run code. That code can delete files, crash systems, or leak credentials. Sandboxes ensure failures stay contained and enable horizontal scaling across parallel environments.8
Three levels of isolation, in increasing order of safety:
- Local subprocess / dev-test — isolated process on the local machine; fast, good for experimentation
- Local Docker — container on the host; more isolated, closer to production conditions
- Remote cloud containers — spun up on demand, destroyed when done; safest, horizontally scalable, GPU-capable for heavy workloads Anthropic learned the credential isolation lesson the hard way. An early coupled design ran untrusted agent-generated code in the same container as credentials — one prompt injection was all it took to read the entire environment.9 The structural fix is non-negotiable: credentials must never be reachable from the sandbox where the agent's generated code runs.
3.4 Context Engineering
At the harness level, context engineering is no longer a craft — it is an engineered component that runs on every invocation, deciding what enters the context window and when.3
Three techniques address three distinct problem surfaces:
Compaction — handles conversation history. When token count approaches the limit (e.g., under 200k remaining), the harness compresses older turns. Claude Code implements five distinct compaction strategies: "Snip" prunes older messages quickly but lossily; "Microcompact" targets tool outputs specifically. Two strategies remain behind feature flags — a sign of how unsolved this is at scale.10
Progressive Disclosure — handles tool inputs. Like a skill system: the agent reads the name and description of all available tools first, detects when it needs a specific tool, then loads the full schema into context on demand. Nothing is pre-loaded in bulk. This is the same pattern used in agent skill frameworks — load metadata first, hydrate on demand.
Tool Offloading — handles tool outputs. Instead of loading hundreds of tool schemas into the context window, store them in a dictionary outside the window. The LLM uses only three fixed tools: Search (semantic or fuzzy search to find the right tool), Load (inject that tool's schema into context), and Execute (call the tool). This is meta-programming — the API lives in a dictionary; the LLM always sees only three tools.
This pattern has spread widely. OpenAI Agents SDK added
deferLoading: true. ZeroClaw implements it nearly identically. CrewAI added dynamic tool injection in v1.10.2. If you have more than ~20 tools and you're not doing this, you're wasting tokens on every call.10
3.5 Memory
Production agent memory operates across three tiers:
| Tier | What it is | Lifecycle |
|---|---|---|
| Context window | What the LLM is literally reading right now | Gone after each request |
| RAM | Conversation history and tool results for the current session | Gone when the process exits |
| Filesystem | Markdown files written to disk | Survives across all sessions |
The instinct is to reach for a vector database. The reality is simpler. Claude Code uses a three-layer memory architecture centered on MEMORY.md — storing short references rather than full information. No vector database. No RAG pipeline.11 What fits best is plain Markdown: human-readable, human-editable, and durable. A MEMORY.md index pointing to topic files, an AGENTS.md injected at session start, a claude-progress.txt updated after each work session — memory that survives, that you can inspect, and that the agent can update itself.
Anthropic's long-running agent pattern makes this concrete: an initializer agent runs on the first session, writes a progress file, makes an initial git commit. Every subsequent session reads that file first — durable knowledge transfer from one session to the next, no infrastructure required.12
3.6 Tools
Before the Claude Code source leak on March 31, 2026, many assumed you only needed to give an agent a bash shell. The leaked 512,000 lines of TypeScript revealed the actual architecture: Claude Code is not a chat wrapper. It is a plugin-style architecture where every capability is a discrete, permission-gated tool — BashTool, FileRead, FileWrite, WebFetch, LSP integration, and ~40 others.13
The reason for wrapping tools in MCP rather than exposing raw bash is permission gating. Bash gives the agent everything. MCP gives the agent only what it is allowed to have.
Claude Code's permission system is built on default-deny. Every tool declares isReadOnly (defaults to false — assume it writes) and a risk level. The system layers rule-based checks (alwaysAllow/alwaysDeny), pre-tool-use hooks, and an auto-mode safety classifier on top.10 This is what users see as the approval flow — the choice between auto-approve and human-in-the-loop is the if-else logic inside the MCP tool wrapper itself.
Standard tool set:
| Tool | Purpose |
|---|---|
Bash | General-purpose; agent can write and run scripts on the fly |
Read / Write | File operations with safety checks (path validation, line limits) |
Edit | Targeted in-place edits; replaces specific strings, not full files |
Glob | Find files by name pattern (*.py, src/**/*.ts) |
Grep | Search inside files by content pattern |
Task | Spawn a new subagent — bridge between Tools and Orchestration |
3.7 Agent Loop
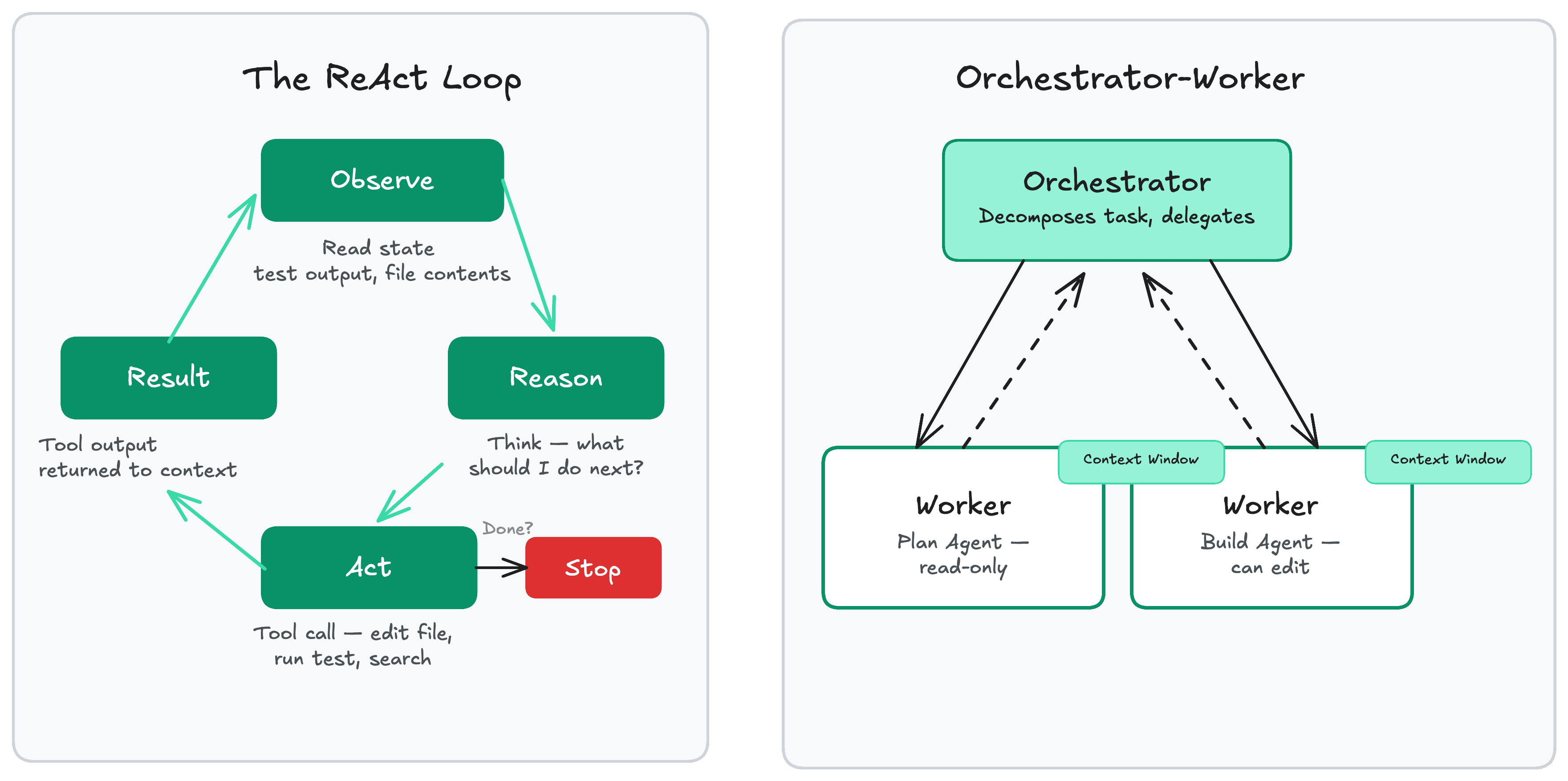
- ReAct Loop (Reasoning + Acting):14
Observe → Reason → Act → Observe → ...
Each Act changes the context, so there is no true loop — each iteration is a new state transition. The generator pattern in Claude Code makes this explicit: every step is a yield, keeping state without a traditional while loop. This lets you test individual stages and add compaction or permission checks as pipeline stages rather than bolted-on callbacks.
- Orchestrator-Worker:
One orchestrator decomposes the task and delegates to specialized workers. Critically, a separate verifier reviews worker output before it is accepted — verification is independent of execution. Inside Claude Code's multi-agent "swarms": one session acts as coordinator, spawns sub-agents with their own tool permissions for parallelizable tasks, and a shared task list with dependency tracking coordinates the work.11
The key difference: ReAct is best for sequential, single-threaded tasks requiring many steps. Orchestrator-Worker is best for tasks that can be parallelized and require independent verification.
References
Footnotes
Thang Chung (2026, April 18). Build an Agent Harness with Microsoft Agent Framework and GitHub Copilot SDK. Global Azure 2026, DevCafe Vietnam. ↩
Bits Bytes NN. (2026, April 5). Evolution of AI Agentic Patterns. https://bits-bytes-nn.github.io/insights/agentic-ai/2026/04/05/evolution-of-ai-agentic-patterns-en.html ↩
Anthropic. (2025, October 22). Effective Context Engineering for AI Agents. https://www.anthropic.com/engineering/effective-context-engineering ↩ ↩2 ↩3 ↩4
LumaDock. (2026, January 23). How to set up OpenClaw across WhatsApp, Telegram, Discord, Slack. https://lumadock.com/tutorials/openclaw-multi-channel-setup ↩ ↩2
OpenClaw. (2026). openclaw npm package. https://www.npmjs.com/package/openclaw ↩
The AI Journal. (2026, April 6). A simplistic understanding of OpenClaw Arch. https://aijourn.com/a-simplistic-understanding-of-openclaw-arch-to-help-you-build-your-own/ ↩ ↩2
Palma.ai. (2026, April 1). Claude Code's Source Leak: What 512K Lines of Code Reveal About MCP. https://palma.ai/blog/claude-code-source-leak-what-it-means-for-mcp ↩
Iusztin, P. (2026, March 31). Agentic Harness Engineering. Decoding AI. https://www.decodingai.com/p/agentic-harness-engineering ↩
Nebius. (2026, March 5). OpenClaw security: architecture and hardening guide. https://nebius.com/blog/posts/openclaw-security ↩
Kubesimplify Blog. (2026, April 1). What Claude Code's Leaked Source Teaches About AI Agents. https://blog.kubesimplify.com/claude-code-leak-what-the-source-actually-teaches ↩ ↩2 ↩3
Bara, M. (2026, April 1). What Claude Code's Source Leak Actually Reveals. https://medium.com/@marc.bara.iniesta/what-claude-codes-source-leak-actually-reveals-e571188ecb81 ↩ ↩2
Anthropic. (2026, March 25). Effective Harnesses for Long-Running Agents. https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents ↩
Hegde, V. (2026, April 1). The Great Claude Code Leak of 2026. DEV Community. https://dev.to/varshithvhegde/the-great-claude-code-leak-of-2026-accident-incompetence-or-the-best-pr-stunt-in-ai-history-3igm ↩
Yao, S., et al. (2022, October). ReAct: Synergizing Reasoning and Acting in Language Models. Princeton University / Google. https://arxiv.org/abs/2210.03629 ↩