I. Introcution
Vector Database is a type of database, designed to store and query unstructured data, which does not have a fixed schema, such as text, images and audio. There are many vector databases available such as Pinecone, Chroma or qdrant.
Vector databases have the capabilities of a traditional database that are absent in standalone vector indexes and the specialization of dealing with vector embeddings, which traditional scalar-based databases lack [1]
This article will introduce the basics of Vector Databases, focusing on Pinecone's capabilities and guiding through the process of setting up own database.
1. Vector embeddings
- Vector refers to an array of numbers with a specific dimensionality.
- Embeddings refers to the technique of representing data as vectors in such a way that captures meaningful information, semantic relationships, or contextual characteristics.
Hence, Vector embeddings are a way of representing text as a set of numbers in high dimensional space (up to two thousand dimensions) and dense (all values are non-zero).
The distance between two embeddings or two vectors measures the relatedness which translate to the relatedness between text concepts they represents. Similar embeddings or vectors represent similar concepts.
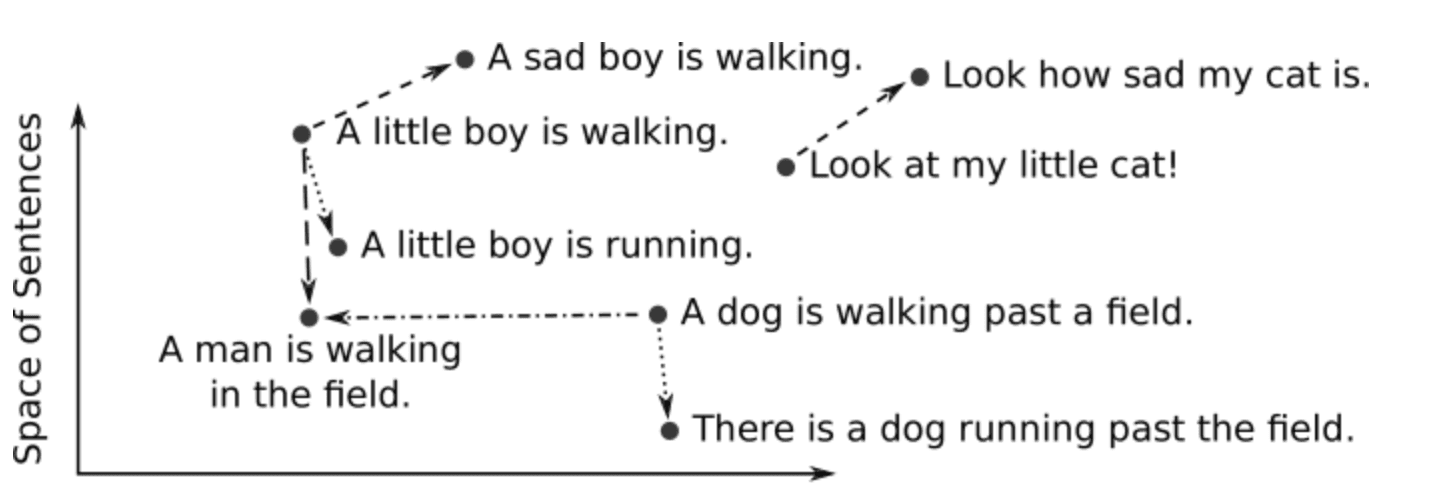
Source: DeepAI
We often train models to translate objects to vectors [2]
- For text data: models such as Word2Vec, GLoVE, and BERT transform words, sentences, or paragraphs into vector embeddings.
- For Images: models such as convolutional neural networks (CNNs)
- For Audio, it can be transformed into vectors using image embedding transformations over the audio frequencies visual representation (e.g., using its Spectrogram).
2. Indexes
An index is the highest-level organizational unit of vector data. It accepts and stores vectors, serves queries over the vectors it contains, and does other vector operations over its contents. [3]
- Serverless indexes:
- Not configure or manage any compute or storage resources
- Scale automatically based on usage (based on a breakthough architecture)
- Pod-based architecture
- Pre-configured units of hardware (pods)
- Depending on the pod type, pod size, and number of pods used, having different amounts of storage and higher or lower latency and throughput
II. Pipeline for Vector Databases
Vector databased use a combination of different optimized algorithms that all participate in Approximate Nearest Neighbor (ANN) search.
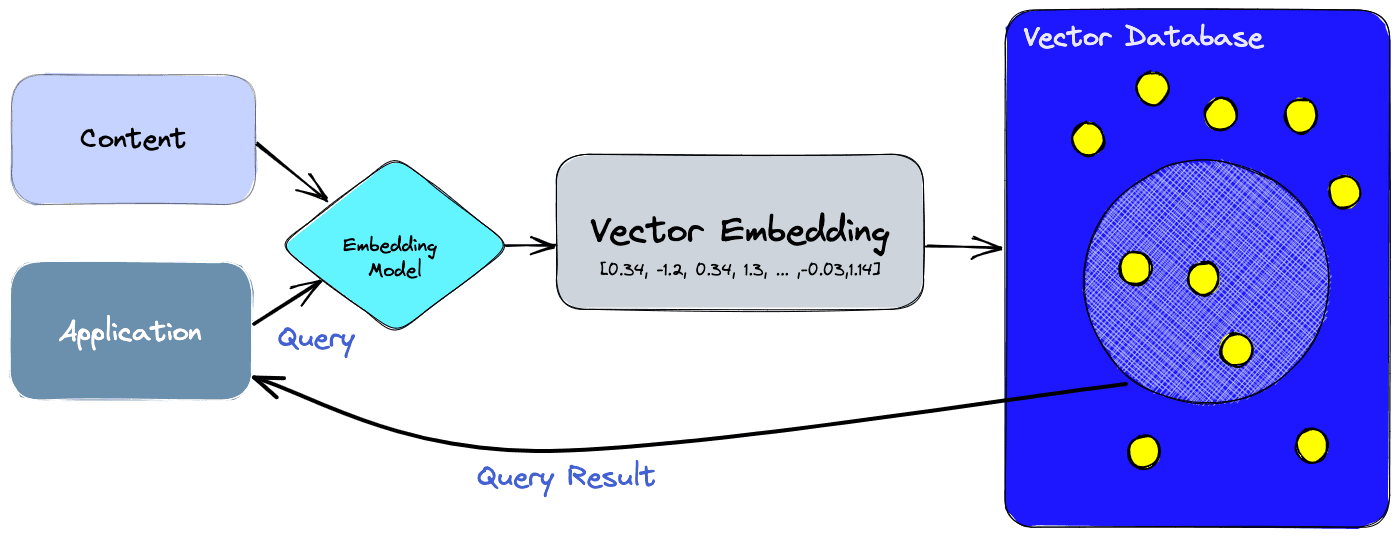
Source: What is a Vector Database & How Does it Work? Use Cases + Examples
This image can be broken down into 3 steps:
- Embedding: Creating Vector Embedding for the content to be indexed.
- Indexing: Inserting the Vector Embeddings into the Vector Database by associating each vector embedding with a reference to the original content used to create it.
- Querying: Searching the vector database for similar content by using the same embedding model used to create the vector embedding. This vector embedding is then used to query the database for similar vector embeddings, which are associated with the original content used to create them.
For example: Storing and querying documents
- First, using an embedding model to create vector embeddings for each document.
- Second, inserting these vector embeddings into a vector database. Each vector embedding would be associated with a reference to the original document.
- Finally, using the vector database to query for information that is similar to a given query or question.
III. Set up a Pinecone vector database
1. Install a Pinecone client
pip install pinecone-client
2. Get API key
- Sign up Pinecone
- Open the Pinecone console.
- Go to API Keys.
- Create / Copy your API key.
3. Initialize client connection
Create a file named .env at the root level to store PINECONE_API_KEY and initialize client connection to Pinecone
import os
from dotenv import load_dotenv, find_dotenv
# loading the API Keys from .env
load_dotenv(find_dotenv(), override=True)
from pinecone import Pinecone
pc = Pinecone(api_key=os.environ.get('PINECONE_API_KEY'))
4. Create a Index
On the free Starter plan, you get one project and one pod-based starter index with enough resources to support 100,000 vectors. However, the Starter plan does not support all Pinecone features. Starter indexes are hosted in the gcp-starter environment, which is us-central-1 (Iowa) region of the GCP cloud. To create a free starter index, import the PodSpec class and set environment="gcp-starter" in the spec parameter [5]
4.1. Options 1: Creates an Starter index using the API key stored in the client 'pinecone'.
from pinecone import Pinecone, PodSpec
pc = Pinecone(api_key=os.environ.get('PINECONE_API_KEY'))
pc.create_index(
name="starter-index",
dimension=1536,
metric="cosine",
spec=PodSpec(
environment="gcp-starter"
)
)
4.2. Options 2: Creates an index on Pinecone Console
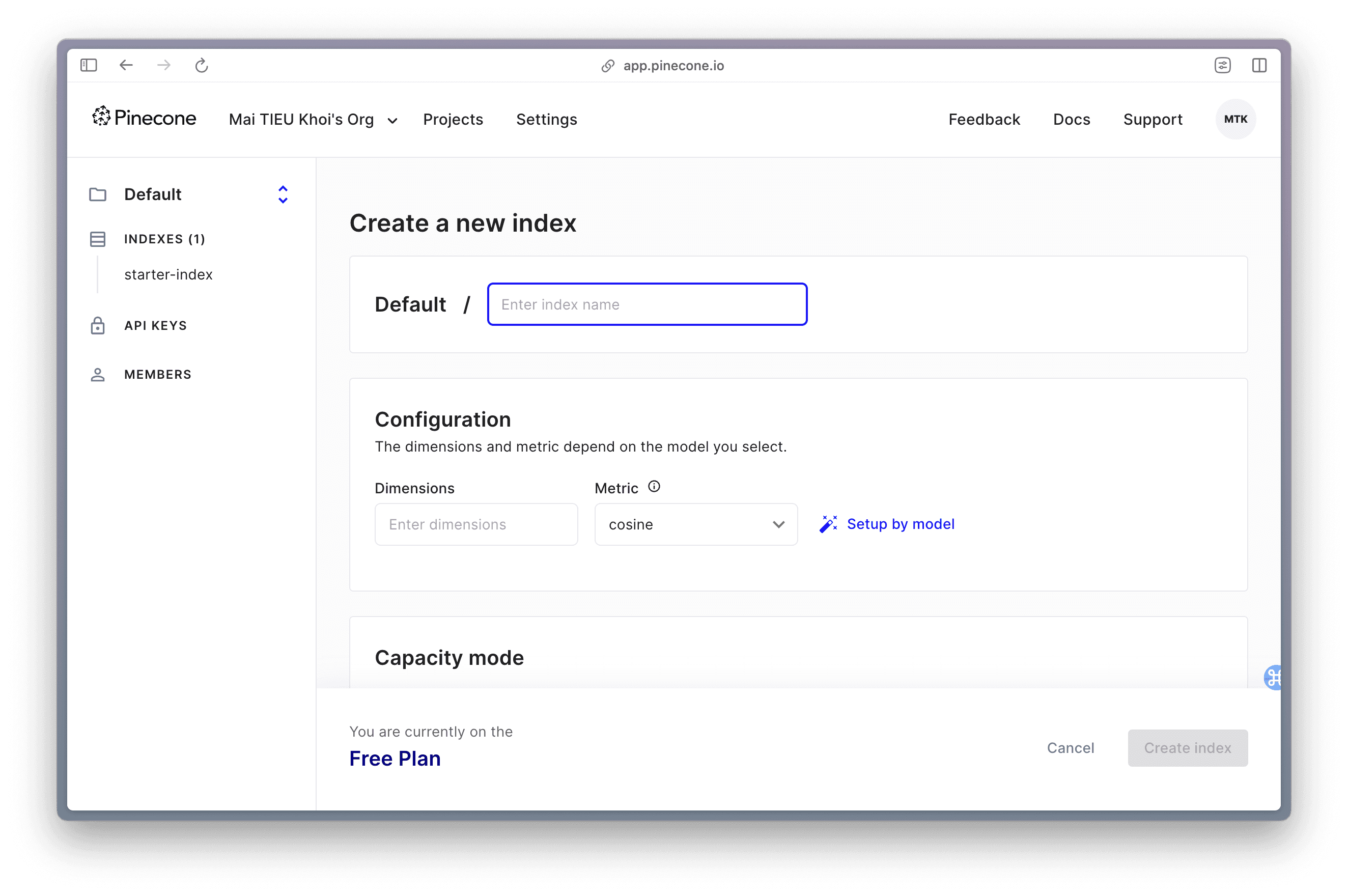
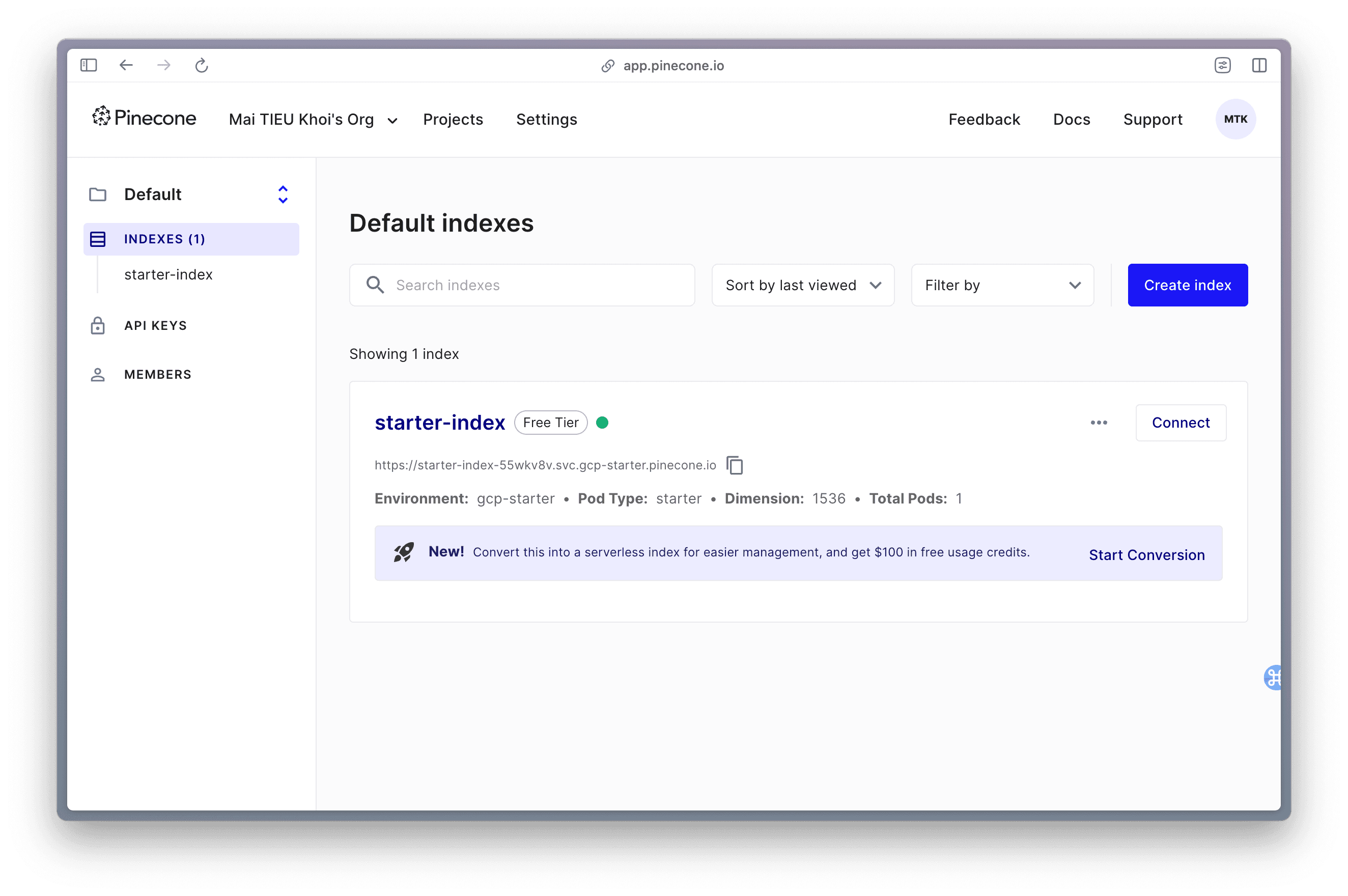
5. Working with Pinecone Index
- Retrieve a description of all indices within a project. It returns a list of dictionaries
pc.list_indexes()
# Returns:
# {'indexes': [{'dimension': 1536,
# 'host': 'starter-index-55wkv8v.svc.gcp-starter.pinecone.io',
# 'metric': 'cosine',
# 'name': 'starter-index',
# 'spec': {'pod': {'environment': 'gcp-starter',
# 'pod_type': 'starter',
# 'pods': 1,
# 'replicas': 1,
# 'shards': 1}},
# 'status': {'ready': True, 'state': 'Ready'}}]}
- To obtain the name of the initial index, we can retrieve the value of the
namekey or invoke thenamemethod.
pc.list_indexes()[0]['name']
# Returns: 'starter-index'
pc.list_indexes().names()
# Returns: ['starter-index']
- So
pc.list_indexes()is equivalent topc.describe_index('starter-index') - To select an index, using
pc.Index()withstarter-indexas an argument and thedescribe_index_statsoperation to display some statistic about it. Note that serverless indexes automatically scale, so the concept ofindex_fullnessmainly applies to pod-based indexes.
index_name = 'starter-index'
index = pc.Index(index_name)
index.describe_index_stats()
# Returns:
# {'dimension': 1536,
# 'index_fullness': 0.0,
# 'namespaces': {},
# 'total_vector_count': 0}
- When the
starter-indexis no longer needed, use the delete_index operation to delete it.
pc.delete_index('starter-index')
6. Working with Vectors
- Generating eight random 1536-dimensional vectors. To insert a vector, we need the vector itself and its ID.
import random
vectors = [[random.random() for _ in range(1536)] for _ in range(8)]
ids = [str(i) for i in range(8)]
6.1. upsert - inserting a new value or updating an existing value
Inserting vector
index.upsert(vectors=zip(ids, vectors)) # Returns: {'upserted_count': 8}Updating vector
index.upsert(vectors=[('1', [0.5]* 1536)]) # Returns: {'upserted_count': 1}
6.2. fetch - selecting a vector by ids
index.fetch(ids=['1','2'])
# Returns:
# {'namespace': '',
# 'usage': {'read_units': 1},
# 'vectors': {'1': {'id': '1',
# 'values': [0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# 0.5,
# ...
# 0.543765485,
# 0.384837836,
# 0.904230714,
# 0.637860656,
# 0.573778749]}}}
If we fetch a vector that does not exist, it will return an empty vector.
index.fetch(ids=['x'])
# Returns:
# {'namespace': '', 'usage': {'read_units': 1}, 'vectors': {}}
6.3. delete - deleting vector by ids
index.delete(ids=['2','3'])
Next, use the describe_index_stats operation to verify if the current vector count matches the number of vectors we inserted or deleted.
index.describe_index_stats()
# Returns:
# {'dimension': 1536,
# 'index_fullness': 6e-05,
# 'namespaces': {'': {'vector_count': 6}},
# 'total_vector_count': 6}
6.4. query - run a similarity search
Retrieve from the index the three vectors that are most similar to a given 1536-dimensional example vector using the Euclidean distance metric.
query_vector = [random.random() for _ in range(1536)]
index.query(
vector=[query_vector],
top_k=3,
include_values=False
)
# Returns:
# {'matches': [{'id': '1', 'score': 0.867275953, 'values': []},
# {'id': '0', 'score': 0.758308589, 'values': []},
# {'id': '4', 'score': 0.754492044, 'values': []}],
# 'namespace': '',
# 'usage': {'read_units': 5}}
7. Namespace
Pinecone allows you to partition the records in an index into namespaces. Queries and other operations are then limited to one namespace, so different requests can search different subsets of your index. [6]
- Every index consists of one or more namespaces.
- Each vector exists in excatly one namespace.
- Namespaces are uniquely identified by a namespace name.
- The default namespace is represented by the empty string and is used if no specific namespace is specifies
For instance, we create two namespaces as shown below:
vectors = [[random.random() for _ in range(1536)] for _ in range(3)]
ids = list('xyz')
index.upsert(vectors=zip(ids, vectors),
namespace='my-first-namespace')
# Returns:
# {'upserted_count': 3}
vectors = [[random.random() for _ in range(1536)] for _ in range(2)]
ids = list('ab')
index.upsert(vectors=zip(ids, vectors),
namespace='my-second-namespace')
# Returns:
# {'upserted_count': 2}
Then, utilize the describe_index_stats method to check. It returns statistics specific to each namespace regarding the contents of all namespaces within an index.
index.describe_index_stats()
# Returns:
# {'dimension': 1536,
# 'index_fullness': 0.00011,
# 'namespaces': {'': {'vector_count': 6},
# 'my-first-namespace': {'vector_count': 3},
# 'my-second-namespace': {'vector_count': 2}},
# 'total_vector_count': 11}
When fetching the vector x using index.fetch(ids=['x']), it will return an empty vector because it queries the default namespace. Therefore, we have to specify that namespace as a parameter, and this applies to any other operation as well.
index.fetch(ids=['x'], namespace='my-first-namespace')
# Returns:
# {'namespace': 'my-first-namespace',
# 'usage': {'read_units': 1},
# 'vectors': {'x': {'id': 'x',
# 'values': [0.444425315,
# 0.861066103,
# 0.603359044,
# 0.440977573,
# 0.37600714,
# 0.0567910224,
# 0.397714078,
# 0.727806807,
# 0.963207304,
# 0.0566852391,
# 0.850490749,
# 0.117750764,
# 0.92188096,
# 0.521925747,
# 0.614547491,
# 0.305061221,
# 0.534375846,
# 0.236293018,
# 0.311549097,
# 0.0850808546,
# 0.731478393,
# 0.345490098,
# ...
# 0.519023,
# 0.0598691516,
# 0.225333884,
# 0.943653941,
# 0.541106284]}}}
In conclusion, we can execute queries and other operations by specifying that namespace as a parameter.
query_vector = [random.random() for _ in range(1536)]
index.query(
vector=[query_vector],
top_k=1,
namespace='my-first-namespace',
include_values=False
)
# Returns:
# {'matches': [{'id': 'y', 'score': 0.75428915, 'values': []}],
# 'namespace': 'my-first-namespace',
# 'usage': {'read_units': 5}}