- Published on
LLMs in LangChain - Part 2. LLMs Core Concepts
- Authors

- Name
- Mai Khoi TIEU
- @tieukhoimai
Table of Contents
I. LLM components
1. LLM Wrappers
LLMs are simply an intermediate that allows one to connect to all popular LLMs and can be organized into three main components:
ChatModelWrapper: Facilitates interactions with chat-based models designed for back-and-forth conversations, managing conversation history, message formatting, and response generation.CompletionModelWrapper: Interacts with text completion models to generate text based on prompts, maintaining memory of past interactions and dynamically managing the text fed to the model.LLMWrapper: The primary interface allowing the selection between chat-based models and text completion models based on themodel_typeparameter.
2. Prompt Template
Prompt refers to the inputs to the model and can be classified into three types based on their contextual information [2]
(i) Zero-shot prompts - These prompts don’t contain examples for the model to replicate. Zero-shot prompts essentially show the model’s ability to complete the prompt without any additional examples or information. It means the model has to rely on its pre-existing knowledge to generate a plausible answer.
- Instruction-content
- Instruction-content-instruction
- Continuation
(ii) One-shot prompts - These prompts provide the model with a single example to replicate and continue the pattern. This allows for the generation of predictable responses from the model.
(iii) Few-shot prompts - These prompts provide the model with multiple examples to replicate. Use few-shot prompts to complete complicated tasks, such as synthesizing data based on a pattern.
Prompt Templates are a way to create a dynamic prompts for LLMs. In LangChain there are
PromptTemplatesandChatPromptTemplates*(ii) Prompt Templates are used for tasks that involve generating text, such as answering questions or completing sentences*
from langchain.prompts import PromptTemplate # Define a template for the prompt template = '''You are an experienced AI Engineer. Write a few sentences about the following concept "{concept}" in {fields}.''' # Create a PromptTemplate object from the template prompt_template = PromptTemplate.from_template(template=template) # Fill in the variable prompt = prompt_template.format(concept='prompt templates', fields='LLMs') # Returns the generated prompt prompt # Output: # 'You are an experienced AI Engineer.\nWrite a few sentences about the following concept "prompt templates" in LLMs.'llm = ChatOpenAI(model_name='gpt-3.5-turbo', temperature=0) output = llm.invoke(prompt) print(output.content) # Output: # Prompt templates in LLMs refer to predefined structures or formats that guide users in generating effective prompts for the language model. These templates help users frame their input in a way that maximizes the model's understanding and response accuracy. By providing a framework for crafting prompts, template can streamline the process of interacting with LLMs and improve the quality of generated outputs. Additionally, prompt templates can also help users explore different types of prompts and experiment with various input styles to achieve desired results.*(ii) Chat Prompt Templates are specifically designed for tasks that involve engaging in conversations*
# Create a chat template with system and human messages chat_template = ChatPromptTemplate.from_messages( [ SystemMessage(content='You respond only in the JSON format.'), HumanMessagePromptTemplate.from_template('Top {n} countries in {area} by population.') ] ) # Fill in the specific values for n and area messages = chat_template.format_messages(n='5', area='World') print(messages) # Outputs the formatted chat messages # Output: # [SystemMessage(content='You respond only in the JSON format.'), HumanMessage(content='Top 5 countries in World by population.')]from langchain_openai import ChatOpenAI llm = ChatOpenAI() output = llm.invoke(messages) print(output.content) # Output: # { # "data": [ # { # "country": "China", # "population": 1444216107 # }, # { # "country": "India", # "population": 1393409038 # }, # { # "country": "United States", # "population": 332915073 # }, # { # "country": "Indonesia", # "population": 276361783 # }, # { # "country": "Pakistan", # "population": 225199937 # } # ] # }
3. Indexing
Indexing involves structuring documents and texts to enable LLMs to extract useful information efficiently. In LangChain, indexing is designed to optimize how documents are stored and retrieved within vector stores. These vector stores are specialized databases that excel in handling high-dimensional data points represented in vector embeddings.
For more detail, the indexing process in vector database [3] typically uses algorithms like Product Quantization (PQ), Locality-Sensitive Hashing (LSH), or Hierarchical Navigable Small World (HNSW) to map the vector embeddings of the data into a specialized data structure.
4. Memory
Memories can be used to save conversation history and feed it along with new questions to LLM so multi-turn natural conversation chat can be implemented.
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferMemory
llm = ChatOpenAI(model='gpt-3.5-turbo', temperature=0)
conversation = ConversationChain(llm=llm)
conversation_buf = ConversationChain(
llm=llm,
memory=ConversationBufferMemory()
)
Several types of conversational memory can be used with the ConversationChain, modifying the text passed to the {history} parameter [4].
- ConversationBufferMemory: The simplest form of conversational memory in LangChain. It passes the raw input of past conversations between the human and AI directly to the
{history}parameter. - ConversationSummaryMemory: Reduces token usage by summarizing the conversation history before passing it to the
{history}parameter. - ConversationBufferWindowMemory: Functions like buffer memory but includes a window, retaining only a specified number of past interactions before discarding the rest.
II. Chains
- Chains are a series of steps and actions. The Chains API includes the basic
LLMChainthat combines an LLM with a prompt to generate output, as well as more advanced chains for building sophisticated LLM apps. - For example, the output of the first LLM chain can be the input/prompt of another chain, or a chain can have multiple inputs and/or multiple outputs, either pre-defined or dynamically decided by the LLM output of a prompt.
1. Simple Chains
from langchain.chains import LLMChain
template = 'What is the capital of {country}?. List the top 3 places to visit in that city. Use bullet points'
prompt_template = PromptTemplate.from_template(template=template)
# Initialize an LLMChain with the ChatOpenAI model and the prompt template
chain = LLMChain(
llm=llm,
prompt=prompt_template,
verbose=True
)
country = input('Enter Country: ')
# Invoke the chain with specific country
output = chain.invoke(country)
print(output['text'])
Enter Country: Vietnam
> Entering new LLMChain chain...
Prompt after formatting:
What is the capital of Vietnam?. List the top 3 places to visit in that city. Use bullet points
> Finished chain.
The capital of Vietnam is Hanoi.
Top 3 places to visit in Hanoi:
- Hoan Kiem Lake and Ngoc Son Temple
- The Old Quarter
- Ho Chi Minh Mausoleum
2. Sequential Chains
Sequential Chains allow a series of calls to one or more LLMs, using the output from one chain as the input to another. There are two types of Sequential Chains:
- SimpleSequentialChains: A series of chains where each chain has a single input and single output, with the output of one step used as the input to the next.
- General form of Sequential Chains: More flexible chains that can have multiple inputs and outputs.
from langchain_openai import ChatOpenAI
from langchain import PromptTemplate
from langchain.chains import LLMChain, SimpleSequentialChain
# Initialize the first ChatOpenAI model (gpt-3.5-turbo) with specific temperature
llm1 = ChatOpenAI(model_name='gpt-3.5-turbo', temperature=0.5)
# Define the first prompt template
prompt_template1 = PromptTemplate.from_template(
template='You are an experienced scientist and Python programmer. Write a function that implements the concept of {concept}.'
)
# Create an LLMChain using the first model and the prompt template
chain1 = LLMChain(llm=llm1, prompt=prompt_template1)
# Initialize the second ChatOpenAI model (gpt-4-turbo) with specific temperature
llm2 = ChatOpenAI(model_name='gpt-4-turbo-preview', temperature=1.2)
# Define the second prompt template
prompt_template2 = PromptTemplate.from_template(
template='Given the Python function {function}, describe it as detailed as possible.'
)
# Create another LLMChain using the second model and the prompt template
chain2 = LLMChain(llm=llm2, prompt=prompt_template2)
# Combine both chains into a SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[chain1, chain2], verbose=True)
# Invoke the overall chain with the concept "linear regression"
output = overall_chain.invoke('linear regression')
# ------------------------------
# The Python function `linear_regression` is an implementation of simple linear regression, which is a fundamental statistical approach used to model the relationship between a single independent variable (denoted as `x`) and a dependent variable (denoted as `y`). The main goal of this function is to find the best-fitting straight line (also known as the regression line) that describes this relationship. The equation of this line is `y = beta1 * x + beta0`, where `beta1` is the slope of the line, and `beta0` is the y-intercept.
# The implementation details of the `linear_regression` function are explained below:
# 1. **Imports and Dependencies**: The function uses NumPy (imported as `np`), a popular library for numerical computing in Python. NumPy provides efficient ways to handle arrays and mathematical operations, making it an ideal choice for implementing linear regression.
# 2. **Parameters**: The function accepts two parameters, `x` and `y`, which are NumPy arrays of the same length. The elements of `x` represent the independent variable values, and the elements of `y` represent the dependent variable values.
# 3. **Number of Data Points**: The function starts by determining `n`, the number of data points, which is the length of the `x` array (and equivalently, the `y` array).
# 4. **Mean Calculation**: It calculates the mean (average) values of both `x` and `y` using `np.mean()`. These mean values are crucial for determining the slope and intercept of the regression line.
# 5. **Slope (Beta1) and Intercept (Beta0) Calculation**:
# - The slope (`beta1`) of the regression line measures the change in the dependent variable (`y`) for a one-unit change in the independent variable (`x`). It is calculated by dividing the sum of the products of differences between each `x` value and the mean of `x` with corresponding differences between each `y` value and the mean of `y`, by the sum of the squares of differences between each `x` value and the mean of `x`. Mathematically, it is expressed as:
# \[ beta1 = \frac{\sum ((x_i - x_{mean}) * (y_i - y_{mean}))}{\sum ((x_i - x_{mean})^2)} \]
# - The intercept (`beta0`) of the regression line represents the value of `y` when `x` is zero. It is calculated using the relationship between the means of `x` and `y`, and the slope (`beta1`). Mathematically:
# \[ beta0 = y_{mean} - beta1 * x_{mean} \]
# 6. **Return Values**: Finally, the function returns the calculated values of the slope (`beta1`) and intercept (`beta0`) of the regression line.
# To use this function, the user needs to provide arrays of `x` and `y` values, and the function will output the slope and intercept of the line that fits best to these points in the context of least squares fitting. These outputs essentially define the linear equation that best describes the relationship between the independent and dependent variables in the given dataset. The given implementation is a clear example for teaching or understanding the basics of simple linear regression without relying on higher-level APIs or libraries that obfuscate these fundamental calculations.
III. Agents
Agents use an LLM to determine which actions to take and in what order. Actions can include using tools, observing their output, or responding to the user.
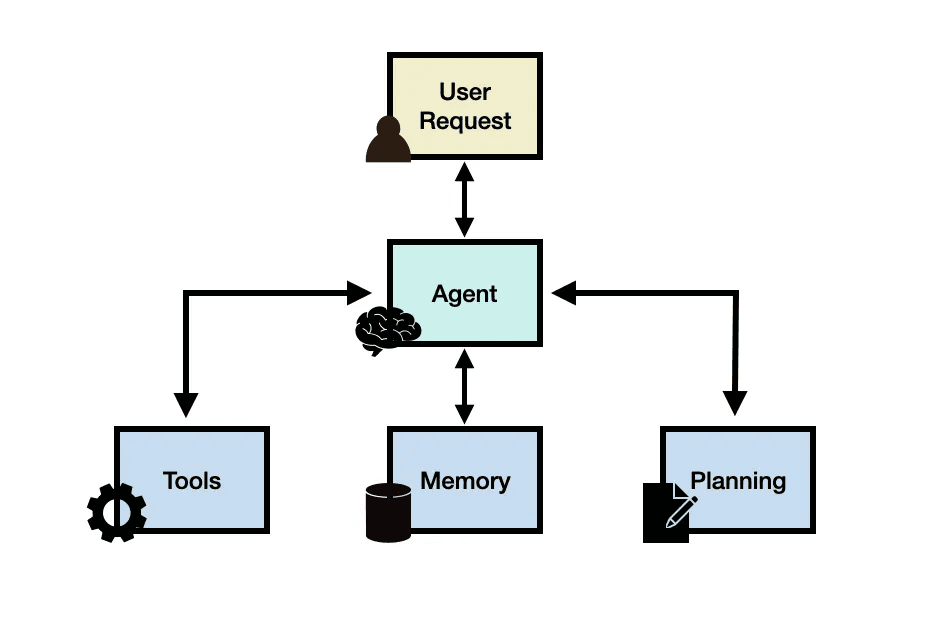
Source: LLM Agents [5]
Tools are entities that take a string as input and return a string as output. They are like specialized apps for LLMs, expanding their capabilities by connecting them to search engines, APIs, and more.
For example, the WikipediaQueryRun tool connects agents and chains to Wikipedia [6].
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
api_wrapper = WikipediaAPIWrapper(top_k_results=1, doc_content_chars_max=10000)
wiki = WikipediaQueryRun(api_wrapper=api_wrapper)
output = wiki.invoke('Google Gemini')
print(output)
Reasoning and Acting (ReAct) is an approach combining reasoning (chain-of-thoughts prompting) and acting capabilities of LLMs. With ReAct, LLMs generate reasoning traces and task-specific actions in an interleaved manner. [1]
💡 LangChain Agent = Tools + Chains
For Example:
- Initialize the LLMs model
- Define and create PromptTemplate
- 3 tools:
- Python REPL tool
- Wikipedia Tool
- DuckDuckGo
# Create tools for the agent
# 1. Python REPL Tool (for executing Python code)
python_repl = PythonREPLTool()
python_repl_tool = Tool(
name='Python REPL',
func=python_repl.run,
description='Useful when you need to use Python to answer a question. You should input Python code.'
)
# 2. Wikipedia Tool (for searching Wikipedia)
api_wrapper = WikipediaAPIWrapper()
wikipedia = WikipediaQueryRun(api_wrapper=api_wrapper)
wikipedia_tool = Tool(
name='Wikipedia',
func=wikipedia.run,
description='Useful for when you need to look up a topic, country, or person on Wikipedia.'
)
# 3. DuckDuckGo Search Tool (for general web searches)
search = DuckDuckGoSearchRun()
duckduckgo_tool = Tool(
name='DuckDuckGo Search',
func=search.run,
description='Useful for when you need to perform an internet search to find information that another tool can\'t provide.'
)
# Combine the tools into a list
tools = [python_repl_tool, wikipedia_tool, duckduckgo_tool]
# Create a react agent with the ChatOpenAI model, tools, and prompt
agent = create_react_agent(llm, tools, prompt)
# Initialize the AgentExecutor
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True,
max_iterations=10
)
Reference
[1] LangChain Mastery: Develop LLM Apps with LangChain & Pinecone
[3] What is a Vector Database & How Does it Work? Use Cases + Examples
[4] Conversational Memory for LLMs with Langchain
[5] LLM Agents
[6] Wikipedia Tools